TCP神奇的40ms延迟
这个问题是很久之前解决的,现在想起来,还是把之前的问题解决过程总结一下。
问题的起因是内部的一个Socket代理,用户对独享数据库的所有请求都需要经过这个Socket代理,某天一个用户反馈,切换到独享数据库之后,页面响应变得异常的慢,大概从1s左右直接到了60s左右,明显是有问题的,首先让用户开了xhprof看了一下,发现用户一个页面牵涉到了超过1000次SQL查询,这1000多次查询占据了绝大部分的时间,因为仅仅切换了数据库,所以问题的原因肯定还是数据库相关。
这个场景还是稍微有点特殊,一个页面里有超过1000次SQL查询的设计也不算合理,所以,我们就编写了测试用例,在PHP中,查询数据库1000次,测试直接连接数据库,和通过Socket代理连接数据库的情况:最后发现直连的速度非常快,但是过代理则慢的不可接受了,很明显是代理的问题。
于是我们尝试在代理机器上抓包分析一下:
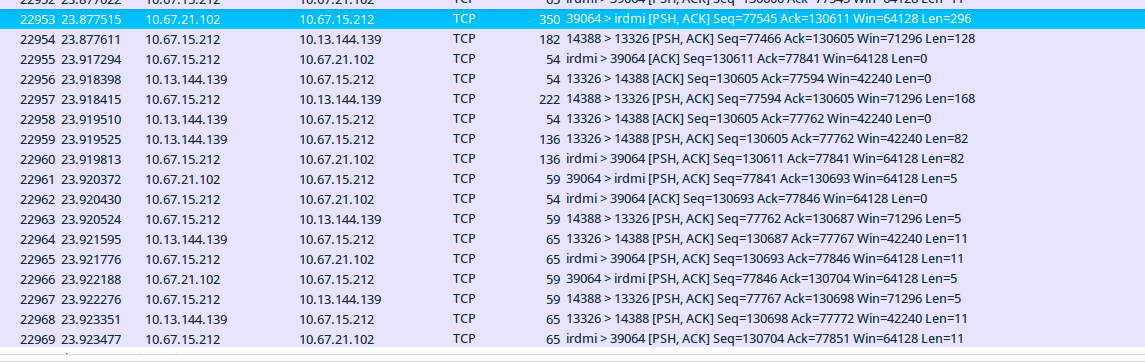
其中10.67.15.102是我们Web运行环境的机器IP,10.67.15.212是Socket代理所在的机器10.13.144.139是数据库所在的机器,从id为22953的数据包开始,到22957,是一个SQL查询从Web运行环境到数据库的整个过程:
id为22953:运行环境102发送select语句到Socket代理212。数据包长度为296byte 时间:23.877515
id为22954:Socket代理212发送了一部分select语句128byte到数据库139。 时间:23.877611
id为22955:Socket代理212回运行环境103的ack。 时间:23.917294
id为22956:数据库139回Socket代理212的ack。 时间:23.918398
id为22957:Socket代理212发送剩余部分select语句168byte到数据库139。 时间:23.918415
这其中有个很奇怪的现象,就是运行环境发送给代理的一条完整的SQL语句,在代理收到并发给数据库的过程中,是分了22954和22957两个数据包发送的,而且,这两次发送之间间隔了23.918415-23.877611=0.0408040s,为什么一个数据包要分两次发送,而且还要间隔差不多40ms呢?首先想到的是不是代码有问题,于是我们在代理机器上strace了一下,看下程序运行的具体状态:
18:42:52.119359 epoll_wait(7, {{EPOLLIN, {u32=38391536, u64=38391536}}}, 1024, 500) = 1 <0.000175>
18:42:52.119672 recvfrom(8, "\240\0\0\0\3SELECT cat_id, cat_name, parent_id, is_show FROM `jiewang300`.`jw_category`WHERE parent_id = '1401' AND is_show = 1 ORDER B", 128, 0, NULL, NULL) = 128 <0.000014>
18:42:52.119758 recvfrom(8, "Y sort_order ASC, cat_id ASC limit 8", 128, 0, NULL, NULL) = 36 <0.000016>
18:42:52.119823 recvfrom(8, 0x24a4494, 92, 0, 0, 0) = -1 EAGAIN (Resource temporarily unavailable) <0.000013>
18:42:52.119929 epoll_wait(7, {{EPOLLOUT, {u32=38394672, u64=38394672}}}, 1024, 500) = 1 <0.000022>
18:42:52.120074 sendto(9, "\240\0\0\0\3SELECT cat_id, cat_name, parent_id, is_show FROM `jiewang300`.`jw_category`WHERE parent_id = '1401' AND is_show = 1 ORDER B", 128, 0, NULL, 0) = 128 <0.000052>
18:42:52.120238 sendto(9, "Y sort_order ASC, cat_id ASC limit 8", 36, 0, NULL, 0) = 36 <0.000022>
18:42:52.120406 epoll_wait(7, {{EPOLLIN, {u32=38394672, u64=38394672}}}, 1024, 500) = 1 <0.041082>
18:42:52.161624 recvfrom(9, "\1\0\0\1\4B\0\0\2\3def\njiewang300\vjw_category\vjw_category\6cat_id\6cat_id\f?\0\5\0\0\0\2#B\0\0\0F\0\0\3\3def\njiewang300\vjw_category\vjw_category\10cat_name\10", 128, 0, NULL, NU
18:42:52.161736 recvfrom(9, "cat_name\f!\0\16\1\0\0\375\1\0\0\0\0H\0\0\4\3def\njiewang300\vjw_category\vjw_category\tparent_id\tparent_id\f?\0\5\0\0\0\2)@\0\0\0D\0\0\5\3def\njiewang300\vjw_category", 128, 0, NUL其中fd 8是和Web运行环境的连接fd,fd 9是和数据库连接的fd,可以看到,程序接收和发送的buffer大小都是128字节,同时,根据第一列的时间可以看到,程序接收完所有数据,就立马通过sendto将数据发送出去了,所以这个40ms的数据包发送延迟应该不是代理程序的问题(不过针对这种场景,可能128字节buffer有点太小了,这也是可以优化的一个点)
不是程序的问题,那肯定就是内核或者其他什么原因导致了这个延迟了,于是搜索了一番,发现确实是内核导致了这个延迟,具体牵扯到两个TCP的机制Nagle's algorithm和TCP delayed acknowledgment,最主要的原因还是因为这个Nagle's algorithm。
Wiki上的解释如下:
Nagle’s algorithm is a means of improving the efficiency of TCP/IP networks by reducing the number of packets that need to be sent over the network. It was defined by John Nagle while working for Ford Aerospace. It was published in 1984 as a Request for Comments (RFC) with title Congestion Control in IP/TCP Internetworks (see RFC 896).
The RFC describes what he called the “small-packet problem”, where an application repeatedly emits data in small chunks, frequently only 1 byte in size. Since TCP packets have a 40-byte header (20 bytes for TCP, 20 bytes for IPv4), this results in a 41-byte packet for 1 byte of useful information, a huge overhead. This situation often occurs in Telnet sessions, where most keypresses generate a single byte of data that is transmitted immediately. Worse, over slow links, many such packets can be in transit at the same time, potentially leading to congestion collapse.
Nagle’s algorithm works by combining a number of small outgoing messages and sending them all at once. Specifically, as long as there is a sent packet for which the sender has received no acknowledgment, the sender should keep buffering its output until it has a full packet’s worth of output, thus allowing output to be sent all at once.
大致意思就是Nagle算法会避免发送小的数据包,增加网络利用率,但是这么做会导致更大的延时。
这个算法大致的伪代码是这样的:
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data sill in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if从伪代码可以看出,在发送队列里有没有确认的数据,并且,新数据包的大小又小于MSS,那么该算法会触发,数据会被缓存,直到待发送的数据总大小大于MSS或者收到了确认的Ack。
其实如果正常来看,这个算法没有问题,因为只要对端回复了ack,数据还是可以立即发送的,但是如果对端开启了TCP delayed acknowledgment功能,数据包的ack被延迟发送,那么,这两个功能一起作用,就会导致延迟。
那怎么避免这个情况发生呢,既然是两个机制共同作用导致的,那就任意破坏其中一个就可以了。关闭TCP delayed acknowledgment功能,或者关闭Nagle's algorithm,很显然,关闭TCP delayed acknowledgment是不明智的,因为多回复的那个ack,实际并没有很大的必要,反而还多增加了延迟。
好在TCP提供了关闭Nagle's algorithm的办法,也就是使用setsockopt设置TCP_NODELAY选项,即可关闭Nagle's algorithm。
在程序中设置了TCP_NODELAY选项后,问题解决。
参考: