一个virtio-blk设备IO大小的问题
最近在测试我们的VM时,发现了一个比较奇怪的现象:对于同样的一个IO压力,当IO设备是NVMe或者virtio-blk时,行为有一些不太一样,具体表现在IOPS上,而且差距非常大,同样是1GB/s左右的IO,两个不同设备的IOPS差了接近4倍:
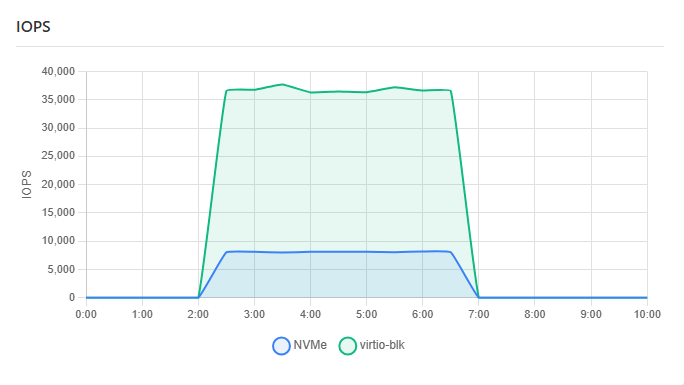
更多的测试
一般来说,NVMe设备,单个IO的最大大小是128KB,那对于1GB/s的吞吐来说,当前的IOPS是一个合理的值,那问题很显然出在了virtio-blk设备上,可以确定地是,在virtio-blk设备上的IO被切分了。简单除一下,可以大致得到设备层的IO大小大致在30KB附近,按照常理,virtio-blk设备的最大IO大小可不止这点。
为了收集更多的信息,还是多做一些测试,看看设备在不同的IO模型下的具体的表现。使用fio给设备加上一个固定的IO:
# fio -filename=/dev/vdb -direct=1 -iodepth 1 -thread -rw=read -ioengine=libaio -rate_iops=200 -bs=4K -size=200G -numjobs=1 -runtime=5 -group_reporting -name=test然后再使用iostat -x 1命令观察设备层的IO情况,然后就是把-bs=4K参数换成不同的IO大小就行了:
# iostat -x 1
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz
vdb 200.00 800.00 0.00 0.00 0.07 4.00可以看到当bs=4K时,数据是符合预期的,从设备层也观察到了200 r/s的IOPS,平均的IO大小rareq-sz也是4.0K。
下面是不同IO大小下的监控数据整理表:
| IO大小 (K) | r/s | rkB/s | rareq-sz | 放大倍数 |
|---|---|---|---|---|
| 4 | 200.00 | 800.00 | 4.00 | 1.00 |
| 8 | 200.00 | 1600.00 | 8.00 | 1.00 |
| 16 | 200.00 | 3200.00 | 16.00 | 1.00 |
| 32 | 400.00 | 6400.00 | 16.00 | 2.00 |
| 64 | 600.00 | 12800.00 | 21.33 | 3.00 |
| 128 | 1000.00 | 25600.00 | 25.60 | 5.00 |
| 256 | 2000.00 | 51200.00 | 25.60 | 10.00 |
| 512 | 3800.00 | 102400.00 | 26.95 | 19.00 |
可以发现,当前只要超过32K的IO请求,都会被拆成更小的IO,从数据看不难看出设备能接受的最大IO应该在[26.95K 32K)的范围内。
在BCC项目里,提供了一个工具biosnoop,使用这个工具可以抓出来每个提交到设备的请求,尝试使用一下,看看能不能找到一些有用的信息,使用第一个开始拆分的bs=32K进行测试的同时抓取一下IO的提交情况:
# /usr/share/bcc/tools/biosnoop -d /dev/vdb
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 fio 46743 vdb R 56 4096 0.18
0.000103 fio 46743 vdb R 0 28672 0.29
0.004934 fio 46743 vdb R 120 4096 0.14
0.005040 fio 46743 vdb R 64 28672 0.25
0.009920 fio 46743 vdb R 128 28672 0.13
0.010024 fio 46743 vdb R 184 4096 0.23
#...
# 下面是64K的情况
197.473052 fio 48670 vdb R 0 28672 0.25
197.473153 fio 48670 vdb R 56 28672 0.35
197.473157 fio 48670 vdb R 112 8192 0.35
197.477947 fio 48670 vdb R 128 28672 0.17
197.478051 fio 48670 vdb R 240 8192 0.28
197.478053 fio 48670 vdb R 184 28672 0.28
197.482997 fio 48670 vdb R 256 28672 0.22
197.483098 fio 48670 vdb R 312 28672 0.33
197.483100 fio 48670 vdb R 368 8192 0.33可以看到一个32K的请求,被拆分成了28K+4K。虽然在iostat里看到的平均IO大小是16K,但实际上可以发现,真正到设备的IO并不是2个16K,换了其他的IO大小继续压测,发现提交到设备的IO始终无法突破28K这个“坎”。
设备的限制
在Linux的块设备中,有几个重要的参数决定了设备能够接受的最大IO大小,他们分别是max_segments,max_segment_size和max_sectors_kb,以NVMe为例:
# cat /sys/class/block/nvme0n1/queue/max_segments
33
# cat /sys/class/block/nvme0n1/queue/max_segment_size
4294967295
# cat /sys/class/block/nvme0n1/queue/max_sectors_kb
128怎么理解这几个数值呢,咱们可以结合struct bio的定义看:
struct bio_vec {
struct page *bv_page;
unsigned short bv_len;
unsigned short bv_offset;
};
/*
* main unit of I/O for the block layer and lower layers (ie drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev; /* target device */
unsigned long bi_flags; /* status, command, etc */
unsigned long bi_opf; /* low bits: r/w, high: priority */
unsigned int bi_vcnt; /* how may bio_vec's */
struct bvec_iter bi_iter; /* current index into bio_vec array */
unsigned int bi_size; /* total size in bytes */
unsigned short bi_phys_segments; /* segments after physaddr coalesce*/
unsigned short bi_hw_segments; /* segments after DMA remapping */
unsigned int bi_max; /* max bio_vecs we can hold
used as index into pool */
struct bio_vec *bi_io_vec; /* the actual vec list */
bio_end_io_t *bi_end_io; /* bi_end_io (bio) */
atomic_t bi_cnt; /* pin count: free when it hits zero */
void *bi_private;
};每个块层IO可以通过一个struct bio表示,而IO数据存放在struct bio_vec中,于是就有了一个bio最多包含max_segments个bio_vec,每个bio_vec最多包含max_segment_size的数据,同时,每个bio最大不超过max_sectors_kb。
基于上面NVMe设备的这几个参数,不难发现,因为NVMe设备的max_segments*max_segment_size远大于max_sectors_kb,但由于IO不能超过max_sectors_kb的值,因此,对于NVMe而言,最大IO大小也就被限制在了128KB了。
那virtio-blk设备呢?
# cat /sys/class/block/vdb/queue/max_segments
7
# cat /sys/class/block/vdb/queue/max_segment_size
65536
# cat /sys/class/block/vdb/queue/max_sectors_kb
1280可以看到当前的这个设备,最大IO受限于max_segments*max_segment_size,理论上最大IO是512K,但这里有个问题,512K也远大于刚刚biosnoop里看到的28K啊,这又是为什么?
其实看到struct bio_vec定义的瞬间,就应该能猜到原因了,因为一般情况下,bio_vec都会指向一个page页,那正常情况下,page大小就是4K,因此就不能仅仅看max_segment_size所代表的最大值,还要考虑具体的页大小,所以按上面的计算方法,就变成了max_segments*4K,也就是28K了,到这里那一切都说的通了。
参数优化
既然知道了出问题的原因,那解决问题也就很简单了,只需要调整一下max_segments的大小就可以了,由于实际我们的设备驱动是virtio-blk,因此这个值最终取决于VIRTIO_BLK_F_SEG_MAX,VIRTIO_BLK_F_SIZE_MAX这俩个feature以及对于的配置空间参数,这些是需要在virtio backend侧进行设置的,最终,我们把max_segments设置到了64,把max_segment_size设置到了8K,在这样的参数配置下,当页大小为4K时,最大可支持256K的IO大小,可以更好的满足用户的需求了。
再测试一下:
# fio -filename=/dev/vdb -direct=1 -iodepth 1 -thread -rw=read -ioengine=libaio -rate_iops=200 -bs=256K -size=200G -numjobs=1 -runtime=5 -group_reporting -name=test
# iostat -x 1
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz
vdb 200.00 51200.00 0.00 0.00 0.17 256.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz
vdb 200.00 51200.00 0.00 0.00 0.17 256.00嗯,可以看到已经可以处理最大256K的IO了。
OneMoreThing
最后的最后,还有一个事情没有解决,就是有什么场景下,可以利用更大的segment_size从而在segments不增加的情况下,提升最大IO大小的?
理论上,如果IO数据的物理地址连续,那一个page其实是可以大于4K的,在这种情况下,自然就可以实现更大的IO,那怎么造出一个这样的IO呢?说到物理地址连续,很自然的想到了大页内存,大页内存可以保证单个大页使用的物理地址联系,那fio可以使用大页内存么?
答案是肯定的,fio提供了一个-iomem参数用于制定io的内存来源:
# sysctl vm.nr_hugepages=20
# fio -filename=/dev/vdb -direct=1 -iodepth 1 -thread -rw=read -ioengine=libaio -rate_iops=200 -bs=256K -iomem=shmhuge -size=200G -numjobs=1 -runtime=100 -group_reporting -name=test
# iostat -x 1
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz
vdb 200.00 51200.00 0.00 0.00 0.30 256.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz
vdb 200.00 51200.00 0.00 0.00 0.32 256.00嘿,真的可以!如果bs改成512K呢?用biosnoop看下:
/usr/share/bcc/tools/biosnoop -d /dev/vdb
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 fio 53658 vdb R 2115456 65536 0.30
0.000128 fio 53658 vdb R 2114560 458752 0.43
0.005046 fio 53658 vdb R 2115584 458752 0.35
0.005152 fio 53658 vdb R 2116480 65536 0.45
0.009991 fio 53658 vdb R 2117504 65536 0.29
0.010124 fio 53658 vdb R 2116608 458752 0.42没问题,458752刚好就是7*64K的值。
不难发现,使用大页内存,对于IO来说,还是有些正向提升的,只是大多数场景下,业务很难做到这么细致的优化,也许Memory folios的普及可以改变这个现状吧。