一个Linux新老内核对于硬件中断的统计差异
最近接到一个客户反馈,说他们的机器,遇到了top命令中,hardirq的值特别高的问题。
top - 15:27:37 up 43 days, 3:42, 1 user, load average: 44.75, 53.47, 51.66
Tasks: 244 total, 1 running, 243 sleeping, 0 stopped, 0 zombie
%Cpu0 : 10.3 us, 19.8 sy, 0.0 ni, 39.7 id, 0.4 wa, 28.2 hi, 1.6 si, 0.0 st
%Cpu1 : 10.7 us, 21.3 sy, 0.0 ni, 40.7 id, 0.4 wa, 26.1 hi, 0.8 si, 0.0 st
%Cpu2 : 10.0 us, 19.1 sy, 0.0 ni, 41.4 id, 0.4 wa, 27.9 hi, 1.2 si, 0.0 st
%Cpu3 : 10.4 us, 20.7 sy, 0.0 ni, 40.2 id, 0.4 wa, 26.7 hi, 1.6 si, 0.0 st
%Cpu4 : 10.4 us, 15.5 sy, 0.0 ni, 45.4 id, 0.4 wa, 28.3 hi, 0.0 si, 0.0 st
%Cpu5 : 10.8 us, 21.9 sy, 0.0 ni, 39.4 id, 0.4 wa, 27.1 hi, 0.4 si, 0.0 st
%Cpu6 : 10.1 us, 18.6 sy, 0.0 ni, 41.7 id, 0.4 wa, 28.7 hi, 0.4 si, 0.0 st
%Cpu7 : 10.6 us, 25.2 sy, 0.0 ni, 36.6 id, 0.0 wa, 26.4 hi, 1.2 si, 0.0 st从top命令输出可以看到,hardirq的值特别高,超过了25%。这导致了idle的下降,触发了监控的频繁报警。
而同样业务以及相似的业务量情况下,另外一台机器表现就正常许多:
top - 15:31:19 up 118 days, 20:15, 1 user, load average: 93.25, 74.45, 63.84
Tasks: 209 total, 1 running, 208 sleeping, 0 stopped, 0 zombie
%Cpu0 : 5.5 us, 18.2 sy, 0.0 ni, 76.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.8 us, 6.0 sy, 0.0 ni, 90.8 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
%Cpu2 : 6.6 us, 19.8 sy, 0.0 ni, 72.7 id, 0.4 wa, 0.0 hi, 0.4 si, 0.0 st
%Cpu3 : 2.4 us, 6.3 sy, 0.0 ni, 91.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 5.9 us, 17.4 sy, 0.0 ni, 76.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 2.4 us, 7.1 sy, 0.0 ni, 90.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 5.0 us, 18.7 sy, 0.0 ni, 76.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 2.4 us, 6.7 sy, 0.0 ni, 90.6 id, 0.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu8 : 5.1 us, 16.8 sy, 0.0 ni, 77.6 id, 0.0 wa, 0.0 hi, 0.5 si, 0.0 st这俩机器在业务性能表现上是类似的,最大的区别就是hardirq高的机器使用了更新的RockyLinux 9操作系统,内核版本会新一点。而另一台机器还在使用老的CentOS 7操作系统,内核版本会老一点。
初步调查
除了Rocky 9机器hardirq高之外,两台机器的其他各方面指标都非常的相似,比较明显的,两台机器的中断数量以及context switch数量都比较高:
~]$ dstat -y
---system--
int csw
364k 1247k
358k 1242k
384k 1271k
547k 1480k
562k 1505k上下文切换超过了100万次/s。两者的火焰图也十分相似,不过从火焰图上观察,进程会大量调用nanosleep这个系统调用,调用比例和hardirq的比例是类似的:
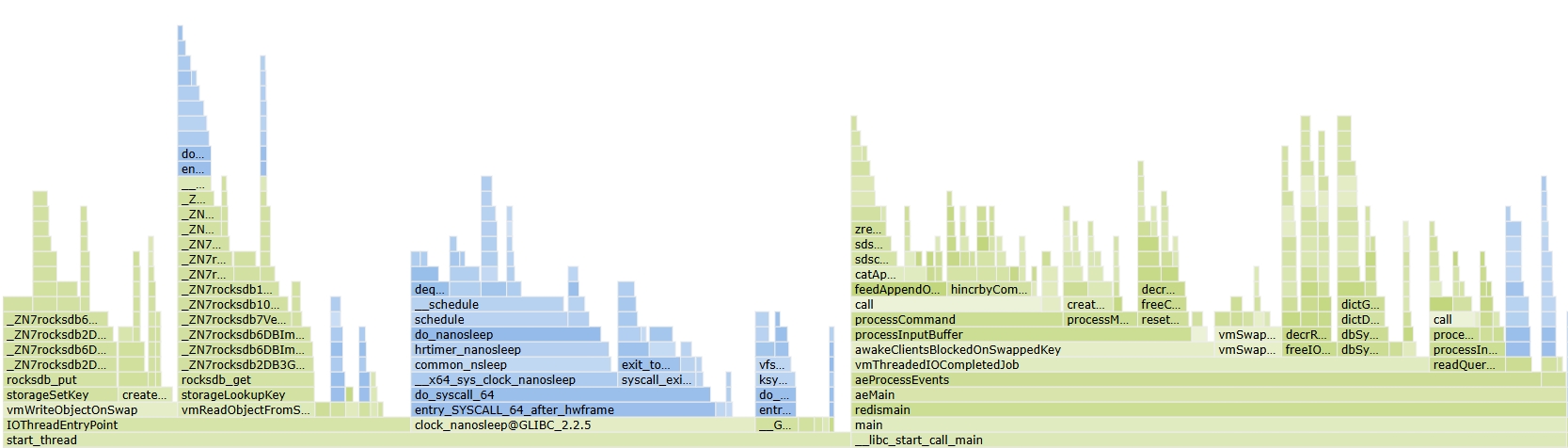
如果是大量nanosleep调用的话,那应该很容易用stress-ng工具复现了。事实证明,使用stress-ng工具可以获得和生产环境非常相似的现象,尝试了Rocky 9.5、CentOS 7.9,物理机、虚拟机的各种组合,结果发现确实和操作系统的内核版本关系很大。
问题分析
在后续分析中,找到了这样一篇资料Is Your Linux Version Hiding Interrupt CPU Usage From You?。
在这篇文章中,作者发现Ubuntu 20.10及其默认Linux内核5.8.0版本的系统中,即使使用fio压测实现了11M IOPS的性能时,dstat和其他监控工具报告的hardirq时间依然为零,而在相同的机器上启动了使用Oracle Enterprise Linux 8.3及5.4.17版本内核时,发现hardirq时间会占用差不多27%的CPU。
这和我们遇到的问题非常相似,他给出了一个关键性的内核配置项CONFIG_IRQ_TIME_ACCOUNTING。
在作者的Ubuntu系统中,CONFIG_IRQ_TIME_ACCOUNTING配置没有被启用,同样的,这个配置在我们的CentOS 7环境里也没有启用(甚至并没有这个配置项):
$ uname -r
3.10.0-1160.el7.x86_64
$ grep CONFIG_IRQ_TIME_ACCOUNTING /boot/config-`uname -r`
$ awk '/^cpu /{ print "HW interrupt svc time " $7 * 10 " ms" }' /proc/stat
HW interrupt svc time 0 ms而在更新的Rocky 9中,该配置被启用了:
$ uname -r
5.14.0-503.23.1.el9_5.x86_64
$ grep CONFIG_IRQ_TIME_ACCOUNTING /boot/config-`uname -r`
CONFIG_IRQ_TIME_ACCOUNTING=y
$ awk '/^cpu /{ print "HW interrupt svc time " $7 * 10 " ms" }' /proc/stat
HW interrupt svc time 432097660 ms可以看到,启用了这个配置后,硬件中断处理程序中花费的时间才会被统计,这也是为什么线上用户会报告硬件中断处理程序中花费的时间不匹配的原因。
一些解释
关于中断时间的统计,文章作者也给了一些解释,这里也翻译一下,供大家参考。
中断处理会影响任何线程的CPU时间,因为中断不关心CPU上正在运行的是什么,它们只是突然接管。这正是它们被称为中断的原因! 更长的解释如下:
首先假设 IRQ 时间统计被禁用:
- 中断可以“随机”地发生在任何时间,这取决于硬件设备何时向 CPU 发出中断信号。
- 当 CPU 恰好在运行某个运行在用户模式的应用程序线程时收到中断信号,中断处理的 CPU 周期将被计入该应用程序进程(正如您在 top 中看到的那样),并显示为 %usr 类型的利用率。
- 当 CPU 恰好仍在运行一个由于发出系统调用而处于内核模式的应用程序线程时收到中断信号,那么中断 CPU 时间将被添加到该应用程序线程,但会显示为 %sys 类型。
- 当 CPU 正在执行内核线程时(并且内核代码路径没有为某些关键部分临时禁用中断),收到中断信号,中断处理的 CPU 时间将被添加到该内核线程的 %sys 模式中。这感觉很直观,因为人们通常认为硬件设备、驱动程序和中断都是内核工作的一部分。
- 这引发了一个有趣的问题:当 CPU 在收到中断信号时恰好处于空闲状态时会发生什么? 像往常一样,这取决于硬件功能,例如电源感知中断路由是否可用,但完全有可能空闲的 CPU 被唤醒并必须使用 CPU 来处理 IRQ。由于 CPU 在空闲时没有运行任何用户/内核线程(没有可用的 task_struct 线程上下文结构),CPU 时间被计入 Linux 内核伪任务 0,该任务在诸如 perf 之类的工具中显示为 swapper。因此,像 top 这样的工具不会在进程列表中显示任何来自“空闲” CPU 的高 IRQ CPU 使用率的进程,但基于 /proc/stat 的系统级工具(如 dstat、mpstat 甚至 top 标头中的系统级摘要)会显示某些东西正在使用 %sys 模式的 CPU。
现在,启用 IRQ 时间统计后:
- 启用 IRQ 时间统计后,硬件中断处理程序将使用 CPU 内置的时间戳计数器读取指令 (rdtsc) 在中断处理操作的入口和出口获取高精度“时间戳”。
- 这些时间增量归因于 %irq 指标,而不是 %usr 或 %sys 线程 CPU 使用率(/proc/stat 每 CPU 都有一行包含 CPU 使用率指标)。
- 像 mpstat 甚至 top 系统摘要部分这样的系统级工具现在将正确地细分 %irq% CPU 使用率。
- 然而,进程/线程级别的指标(如 top 进程列表部分)仍然会将任何 IRQ 时间与 %usr 和 %sys 指标混在一起,因为 Linux 不跟踪进程/线程级别的“意外”IRQ 服务时间。
这只是关于裸机 Linux 服务器上硬件中断处理的简短总结,我不会在此深入探讨。此外,为了保持本文简洁,我特意没有涵盖软件中断或上半部/下半部中断处理延迟架构。 请注意,我运行的是一个合成基准测试,它在用户空间线程中并没有做太多的工作,大部分时间都花在了系统调用和内核块层上。因此,当我们的进程已经处于内核模式时,更可能发生 CPU 处理的“突然”硬件中断。对于一个中断密集型应用程序(例如网络!),它的大部分时间都花在用户空间中,我们会看到更多的 %usr CPU 时间切换到 %hiq。