一个epoll惊群导致的性能问题
在我们内部的系统中,有一个tcp的代理服务,用户所有的网络相关的请求,比如访问外网,或者访问在内网的某些服务,都需要通过这个服务,一方面是实现对外网访问的计费,另外也通过白名单机制,对应用的内网访问进行相应的限制。
随着业务量的增加,发现提供服务的机器负载逐渐变高,当流量高峰的时候,经常出现客户端无法连接的情况,本来这个服务也是一个无状态的服务,可以很方便的水平扩容,在添加机器的同时,也尝试去分析一下程序本身的瓶颈,看能否提升一下程序本身的处理能力,通过分析和优化,还是在一定程度上提升了处理能力
首先还是在线上使用perf工具生成了一下火焰图: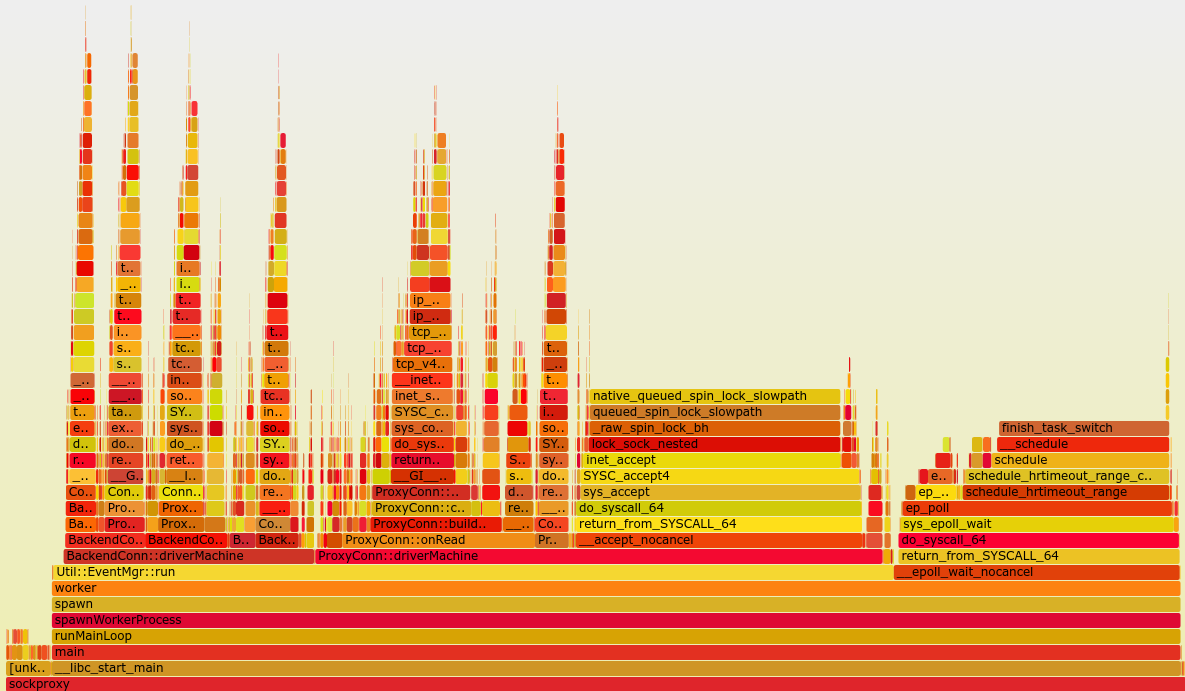
第一次看到这个火焰图感觉很奇怪,主要的问题集中在为什么__accept_nocancel也就是accept的调用会如此频繁,首先想到的就是惊群效应了,但是应该在Linux内核2.6.18的时候,accept的惊群问题在内核中就已经解决了,我们线上用的CentOS 6.5内核版本已经到了2.6.32,理论上不应该会有类似的问题。
于是还是到线上尝试strace看一下程序的系统调用:
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(7, {{EPOLLIN, {u32=9484480, u64=9484480}}}, 1024, 500) = 1
accept(6, 0x7fff90830890, [128]) = -1 EAGAIN (Resource temporarily unavailable)绝大部分都是epoll_wait返回,尝试accept,但是accept返回EAGAIN,这应该就是火焰图中那么多accept调用的原因。又查找了一下资料,发现在epoll编程模型中是不会处理惊群的,当一个socket有事件,内核会唤醒所有监听的epoll_wait调用,从而导致这个问题。
我们先分析一下程序,目前程序的工作流程是:
- master进程启动,bind并监听一系列fd;
- fork n个worker进程;
- 在worker进程中,获取master进程监听的fd,调用
epoll_create创建epoll instance,并监听listen fd的事件; - 如果有新连接,直接accept,然后进入代理流程;
- 重复执行第4步。
由于线上机器是24核,所以线上运行的时候,会fork 24个worker进程,其实,当worker进程数比较少的时候,这个现象体现的不是很明显,但是当worker进程比较多的时候,惊群产生的而外的损耗,看起来已经无法忽略了。
对于这个问题,nginx的解决办法是,创建一个全局的锁,只有拿到这个锁的woker进程,才会去监听listen fd的事件进行accept,当某些条件满足,worker会放弃该锁,并停止监听listen fd事件,由其他woker得到锁后继续监听listen fd事件。
在nginx 1.9.1版本中,支持了一个新的特性reuseport,在Linux 3.9或更新内核中,可以开启SO_REUSEPORT选项,通过操作系统实现类似之前accept的隔离,来避免惊群现象,同时,能更好的利用多核,提升系统性能。
由于类似nginx的accpet锁实现比较复杂,刚好在我们线上系统CentOS 6.5中,SO_REUSEPORT这个特性已经被redhat backport回来了,也就说在CentOS 6.5的2.6.32内核中,也能开启SO_REUSEPORT这个选项,因此就修改了一下proxy的代码,尝试开启SO_REUSEPORT:
- master进程启动;
- fork n个worker进程;
- 在worker进程中,bind并监听一系列fd,在bind之前设置
SO_REUSEPORT选项,调用epoll_create创建epoll instance,并监听listen fd的事件; - 如果有新连接,直接accept,然后进入代理流程;
- 重复执行第4步。
修改后,同样进行strace,当有新连接的时候,只会有一个worker进程被唤醒进行accept,大大提升了效率,再看一眼火焰图: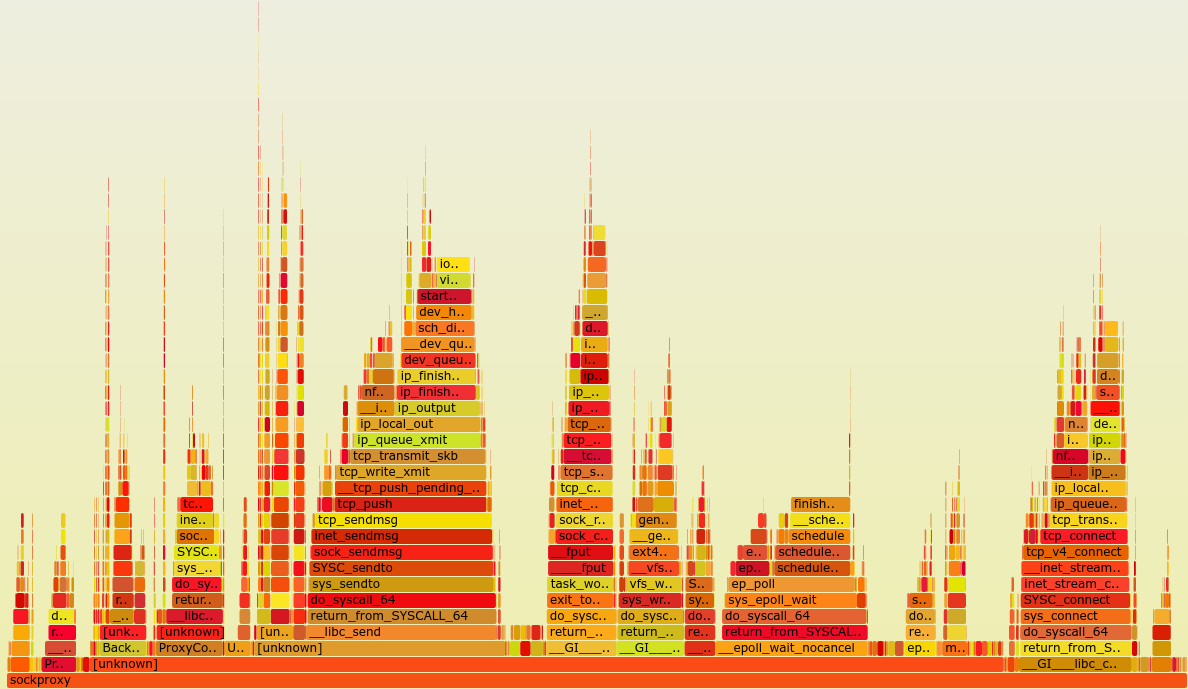
可以看到已经看不到accept的调用了,取代的是recv和send以及connect,对于一个tcp代理来说,实现消耗在网络上,是比较正常的,epoll_wait的调用依然偏多,仍然有优化空间。
通过一个简单的测试,500个线程,50000个请求,在相同机器和配置的情况下,总体时间从约14.38秒减少到约10.27秒,性能大约提升了30%。
PS:在Linux 4.5内核中,引入了EPOLLEXCLUSIVE选项,同样可以解决epoll的惊群问题。 参考:https://github.com/torvalds/linux/commit/df0108c5da561c66c333bb46bfe3c1fc65905898