记一次SAE Web服务器的调优过程
事情的原因,是发生在某个晚上的9点30左右,SAE的报警系统突然报出了异常,所有的Web服务器的负载突然变得很高,流量也变得异常的大。
这个是很有问题的,在SAE最前面的反向代理上,是部署了SAE自己开发的‘CC防火墙’的,如果出现了异常的被攻击的情况,这些异常的流量是不会到达
Web服务器的,现在这些流量都到达了Web服务器,说明要么是攻击没有被正常判断,要没就是这不是一次攻击。
事实上确实这也不是一次攻击。
随后的分析,我们发现了一堆比较‘奇怪’的应用,为什么说‘奇怪’呢,因为这些应用的访问趋势是这样子的:
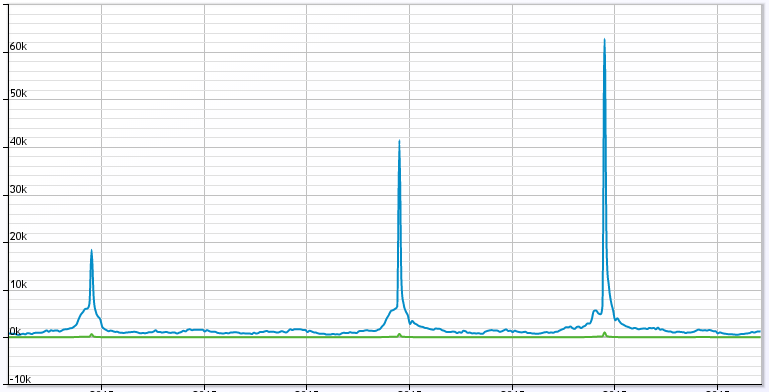
这是其中一个应用的数据,然而在这个应用的帐号下面,大约有十个类似的应用,都是这样的趋势,所以对于我们的Web服务器来说,在特定的时刻要接受
接近10倍左右的流量,对于当前的规模就有点‘顶不住’了。
所以讨论过后,大家的想法还是要对Web服务器进行扩容,来满足这样突发的流量增长。但与此同时,Web服务器也有些不一样的异常,在报警的时候,系统负载
比较高,CPU也没有什么空闲了,但是有个比较特殊的现象,就是system占用的CPU比user占用的CPU要高,这是明显不合理的,一般情况下,system占用CPU较高
意味着系统可能存在瓶颈,比如大量的锁争用等情况。
所以,在着手准备扩容Web服务器的同时,也尝试对现有系统进行一些性能分析,看是否能找到瓶颈,便于做一些优化,提升单Web服务器的容量。
分析的第一步,就是要收集系统运行时的信息,因此我们使用了 perf 这个工具,在系统中对httpd进程进行了抓取,并使用
FlameGraph生成相应的火焰图。
$ perf record -g -a # 等待收集一段时间后Ctrl-c 退出
$ perf script | stackcollapse-perf.pl | flamegraph.pl > flame.svg最终生成的火焰图如下:
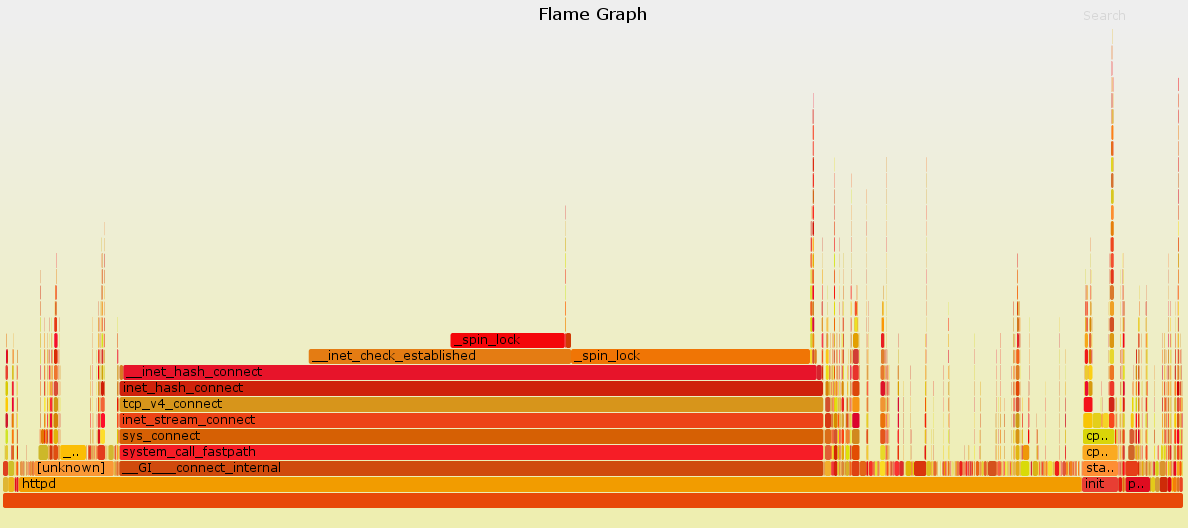
看到这个图,一切都明白了,系统在此阶段调用了太多的connect,尝试建立TCP连接,造成了大量的系统开销,从而影响了整体的性能。
那么为什么会导致这个问题?
用户的代码逻辑非常简单,只是从memcache中取出一个值,然后做一个简单的转换,然后输出。那么,问题就出在了memcache上。
这其实是一个历史遗留问题,SAE的Web服务器是一个纯共享的环境,用户与用户之间,可以做到请求与请求之间的隔离,因此,服务器上的
每个httpd进程都可以为所有的应用服务,实现动态调度,这样的设计,保证了资源的高利用性,能够实现资源利用的最大化。
在当初实现资源隔离的时候,对于memcache,用户初始化memcache时总会帮他建立一个独立的连接,当使用完成,再把连接断掉。
问题就出在了这里,当应用访问量很大,每个请求占用的时间又很短,就出现了频繁和memcache建立连接-断开,又建立连接-断开的死循环。
造成的系统开销非常巨大。
找到了原因,那对应的解决办法就简单了,只需要修改memcache的扩展,把短链接修改为长连接就好,除此之外,如果遇到连接断掉的情况,则
尝试重新连接,保证一个用户的使用不会影响到下个用户。
就这样,最突出的问题就基本解决了。
当然,对于用户来说,其实完全不用关心用的是长连接或者是短连接,不需要调整代码,初始化的Memcache自动地就变成了长连接,完全没有感知。
再看一看调整之后的火焰图:
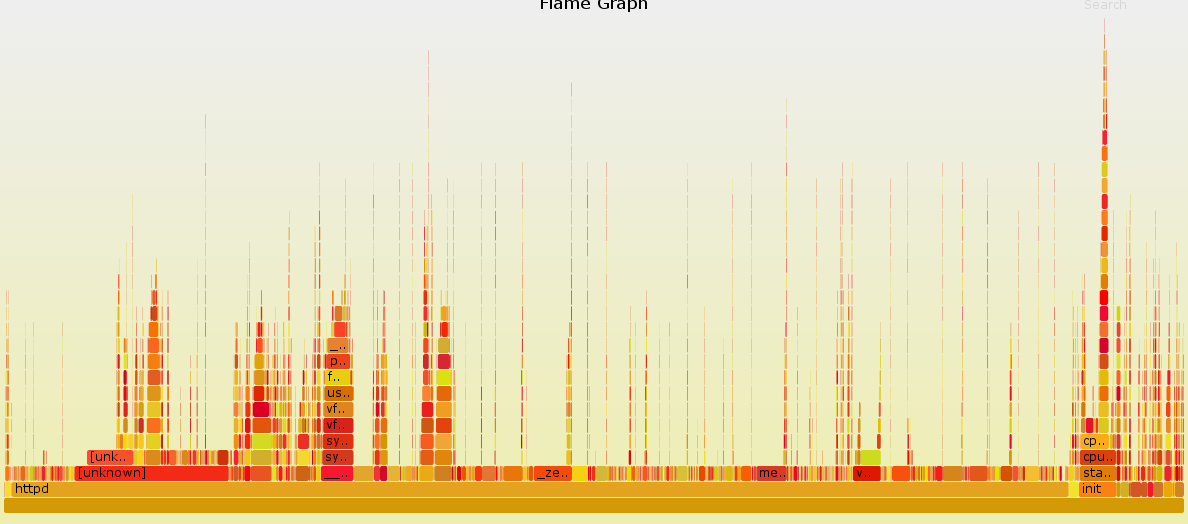
好了不少,没有像之前的火焰图那样非常夸张,相对的消耗都比较平均。
最后在一台即将上线的机器上使用ab测试了一下。
修改前:
Concurrency Level: 100
Time taken for tests: 77.282 seconds
Complete requests: 100000
Failed requests: 3863
(Connect: 0, Receive: 0, Length: 3863, Exceptions: 0)
Write errors: 0
Non-2xx responses: 3863
Total transferred: 29684301 bytes
HTML transferred: 9357111 bytes
Requests per second: 1293.96 [#/sec] (mean)
Time per request: 77.282 [ms] (mean)
Time per request: 0.773 [ms] (mean, across all concurrent requests)
Transfer rate: 375.10 [Kbytes/sec] received修改后:
Concurrency Level: 100
Time taken for tests: 16.554 seconds
Complete requests: 100000
Failed requests: 6080
(Connect: 0, Receive: 0, Length: 6080, Exceptions: 0)
Write errors: 0
Non-2xx responses: 6086
Total transferred: 29450237 bytes
HTML transferred: 9218982 bytes
Requests per second: 6040.76 [#/sec] (mean)
Time per request: 16.554 [ms] (mean)
Time per request: 0.166 [ms] (mean, across all concurrent requests)
Transfer rate: 1737.32 [Kbytes/sec] receivedQPS 从1293.96 [#/sec] 提升到了6040.76 [#/sec],效果还是比较明显的。
修改了memcache的逻辑,又加上扩容了几台服务器,之后,就没有再出现报警的情况,问题算是得到比较好的解决。
当然,使用了长连接之后,服务器维护的连接数会有很大的提升,基本上从原来了200个连接上升到接近2000个连接,不过对于我们的服务器来说,
这些连接其实不算什么,所以其实也不会有太大的影响,和长连接带来的性能提升相比,还是相当值得的。